Recent advances in AI-based image generation has made significant strides in text-image synthesis. In particular, diffusion models stand out by combining context using text prompts to generate very realistic and diverse images for text-to-image generation tasks. These networks have been adapted to various other tasks such as image inpainting, segmentation, style transfer, image to 3D, etc. However, diffusion models struggle to understand and model the spatial and kinematic constraints of the world and therefore perform poorly in depicting complex objects like human faces, body extremities, etc. In this work, we aim to address some of the limitations of diffusion models, in particular, stable diffusion, by optimizing diffusion latents using a mask-aware loss on human faces and body. We hypothesize that conditioning on this loss function will guide the model into focusing on "important" aspects of image generation, like human faces and poses. We believe our work can serve as a foundation for finetuning pre-trained diffusion models on more sophisticated loss functions.
Methodology
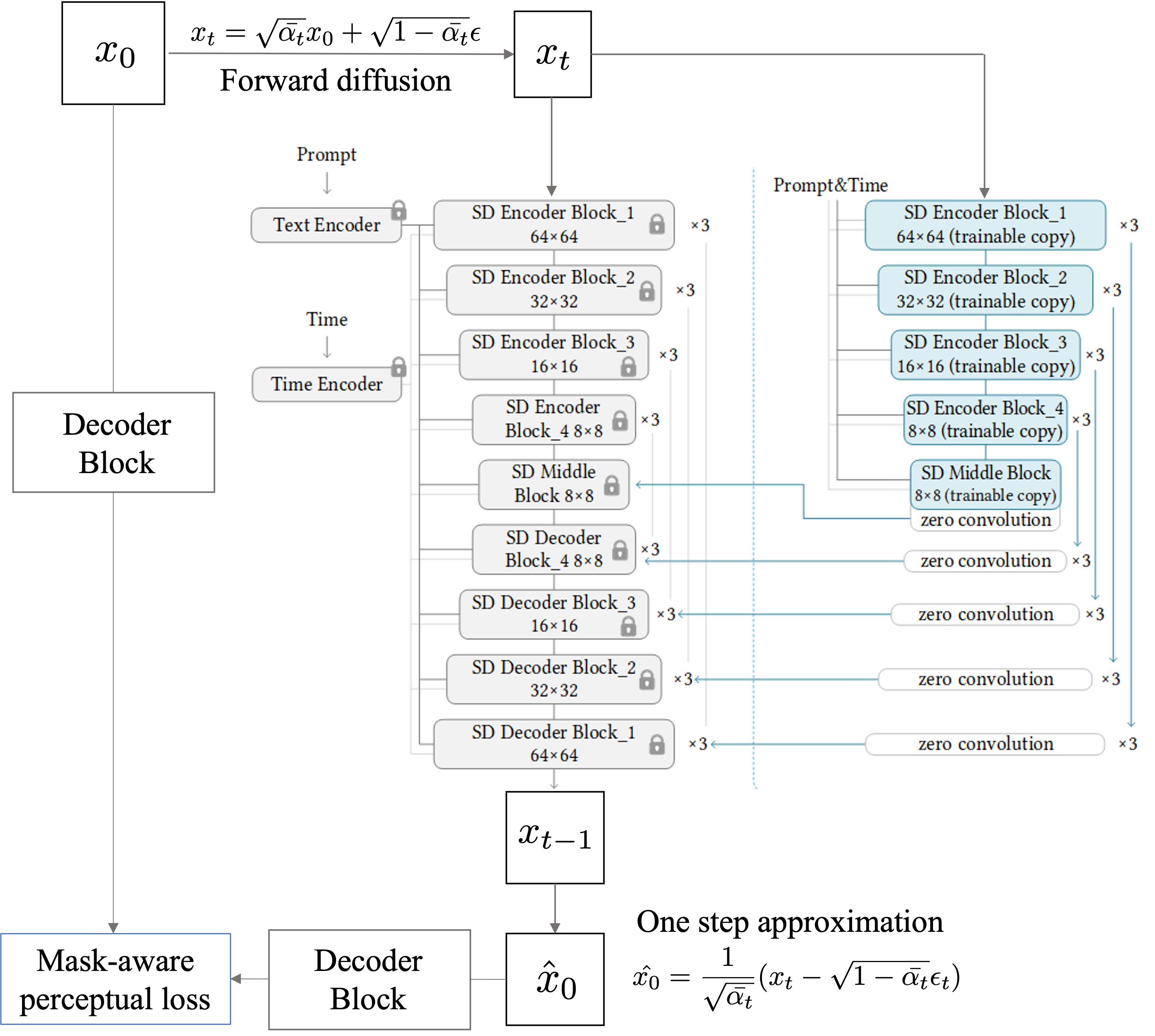
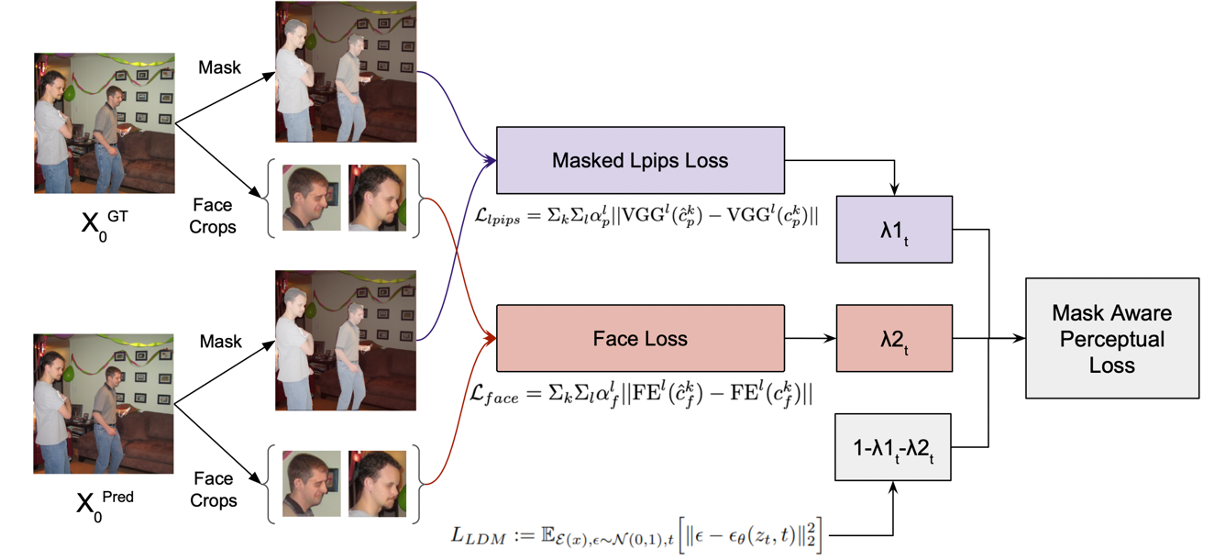
Our broad aim is to control image generation by guiding the diffusion process to minimize a perceptual mask-aware loss function such that it can generate kinematically feasible human poses and realistic facial expressions. We propose using the ControlNet architecture (Figure 1), and instead of using the parallel network to feed in conditioning, we plan to train it as a second modality that guides the diffusion model into minimizing perceptual loss. This loss function is composed of two parts, inspired by Make-a-scene, as shown in Figure 2.
- Face Aware Loss: A feature matching loss over the activations of a pre-trained face embedding network (VGGFace 2)
Lface = Σk Σl αlf ‖FEl (ckf) - FEl (ckf)‖
where l denotes layers in the face embedding network FE, ckf and ckf are the reconstructed and ground truth face crops of k faces in the image, and αfl is a per layer normalization hyperparameter. This face loss helps the model learn low-level features and generate realistic human faces.
- Masked LPIPS Loss: To enforce visual and pose consistency on human images, we additionally use a Learned Perceptual Image Patch Similarity (LPIPS) loss on segmented human masks in the image. LPIPS metric essentially performs a weighted average of multiple feature maps obtained from the VGG network. In order to implement masked LPIPS loss, we first upsample all feature maps to the original input image size and apply segmented human masks on them. Finally, we compute the LPIPS loss on the upsampled VGG feature maps.
Llpips = Σk Σl αlp ‖VGGl (ckp) - VGGl (ckp)‖
where l denotes layers in the VGG, ckp and ckp are the reconstructed and ground truth image mask crops of k people in the image, and αpl is a per layer normalization hyperparameter.
A weighted average of the two loss functions is used to guide the diffusion process and minimize this loss function as represented by:
Ltotal = λ1 Llpips+ λ2 Lface + (1-λ1-λ2) LLDM
We give a weight λ1 to this mask perceptual loss, λ2 to the face loss, and 1-λ1-λ2 to the original LDM loss. The model outputs are noisy at any randomly sampled timestep t, hence, the standard implementation of perceptual loss won't work. One approach could be to use DDIM sampling to reproduce the model output at timestep 0 starting from timestep t. However, this would require running DDIM sampling for k steps and storing the computational graph for them amounts to about 1 TB of GPU memory! To circumvent this issue, we instead use a one-step approximation of the model output from a given timestep t, which is given by the following equation:
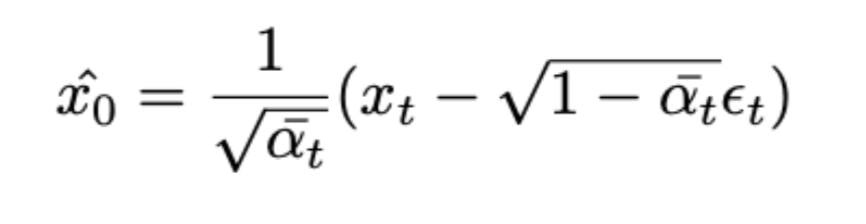

Experiments
Dataset:
MS COCO dataset subset with images that have a significant amount covered by humans. We have a total of 37470 train images and 1565 validation images.
Metrics:
The Frechet Inception Distance (FID) is used to evaluate the quality of generated images with respect to a ground truth dataset. We calculated these scores after every 2 epochs on 1000 validation prompts. It was observed that the FID scores were almost constant throughout training, as seen in Table 1, which may be because the quality of human faces and poses are not captured explicitly. Moreover, we calculated FID on 500 images due to compute limitations, however, recommended settings are atleast 10,000 images. The CLIP score is also not extremely relevant for our use case as it measures the similarity between the generated image and text caption, which is not something we wish to improve. We, therefore, believe that human inspection is the best metric for our use case.
Baseline Setup:
For our baseline, we re-train the ControlNet branch initialized by pre-trained stable diffusion checkpoint 1.5. Our baseline helps us validate whether simply adding a control network without any loss modification is sufficient for getting better image quality. We train the model for 10 epochs, with an output size of 512x512 and a batch size of 2. Each training epoch takes around 6 hours on an RTX 3090 GPU. As seen in row two of Figure 4, the output quality has not improved. This motivated the addition of our mask-aware perceptual loss.
Masked LDM:
We train our model with the mask-aware perceptual loss as described in Figure 2. The model was trained for 12 epochs on an RTX 3090 with an output size of 512x512 and a batch size of 1. There are three hyperparameters that were tuned to get desirable results, the loss timestep threshold T, pose loss scale λ1, and mask loss scale λ2. We observed that when trained with T=400, the generated outputs of the model are blurry, but the human poses generated improved significantly. This can be attributed to the erroneous one-step predictions at high timesteps. Hence a timestep T=100 was chosen to maintain high quality in generated output images. As the face pixels cover a small portion of the image, higher values of λ2 resulted in better face outputs.
Results
Best results were obtained with λ1, λ2, and T=100 and can be seen in the first rows of Figure 4,5,6,7. It can be clearly seen that our method outperforms both our baseline and stable diffusion model outputs. It is necessary to highlight here that no prompt engineering was done to obtain the results. A few failure cases of our model are shown in Figure 8, but here again, it is observed that our model performance is slightly better than the baseline and stable diffusion.





Ablation on T, λ1, and λ2
We observed that when trained with T=400, the human faces and poses improved, but the generated outputs of the model had extremely smooth features. This can be attributed to the smoothening effect in the one-step predictions at high timesteps. Hence a timestep T=100 was chosen to maintain low-level features in generated output images. As the face pixels cover a small portion of the image, higher values of λ2 resulted in better face outputs. Tuning λ1 is again crucial for our setup, as it controls how much the model emphasizes the masked humans. It was observed that λ1 and λ2 greatly determine output quality, while T controls the smoothness in the output image. Figure 9 shows the sampled model outputs after 12 epochs of training on custom prompts using the same random noise vector. It can be seen by human evaluation that the first row with λ1 = 0.2, λ2 = 0.5, T=100 gave the best results, while the second row with λ1 = 0.2, λ2 = 0.5, T=400 gave the second best results.
