Humans are, arguably, one of the most important regions of interest in a visual analysis pipeline. Detecting how the human interacts with the surrounding environment, thus, becomes an important problem and has several potential use-cases. While this has been adequately addressed in the literature in the image setting, there exist very few methods addressing the case for in-the-wild videos. The problem is further exacerbated by the high degree of label skew. To this end, we propose SERVO-HOI (SkEw Robust VideO), a robust end-to-end framework for recognizing human-object interactions from a video, particularly in high label-skew settings. The network contextualizes multiple image representations and is trained to explicitly handle dataset skew. We propose and analyse methods to address the long-tail distribution of the labels and show improvements on the tail-labels. SERVO-HOI outperforms the state-of-the-art by a significant margin (21.2% vs 17.6% mAP) on the large-scale, in-the-wild VidHOI dataset while particularly demonstrating solid improvements in the tail-classes (20.9% vs 17.3% mAP).
In summary, we introduce a novel, state-of-the-art
method to estimate in-the-wild human-object interactions in
videos by exploiting spatial and postural cues and incorporating
multi-label attributes while also addressing the high
degree of dataset skew. A collection of our results on the VidHOI dataset is shown below. We estimate the interaction predicates between the human in green box and the object in the blue, thereby producing a < human, predicate, object > triplet. E.g. in the first image, < boy, holds, toy >
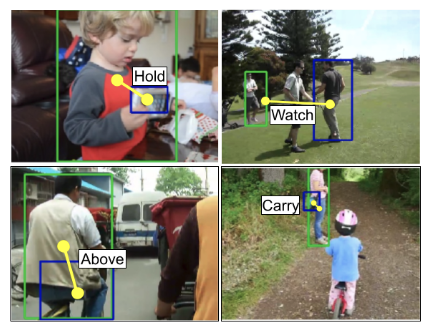
The vidHOI dataset is
a challenging, in-the-wild, and well-annotated dataset and is
is further made difficult, inherently, by the multi-label nature
of the annotations. This is fairly realistic; a human
and an object may interact in more than one ways at the
same time. The dataset also suffers from a high degree of class-imbalance and long-tailed nature as shown:
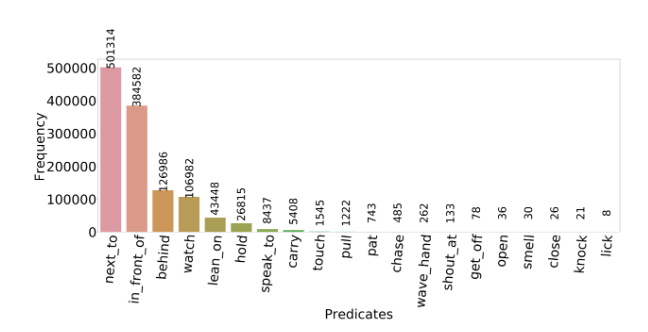
Methodology
With the aforementioned constraints and in mind, we
propose SERVO-HOI – a novel and robust method for
inferring human-object interactions in videos.
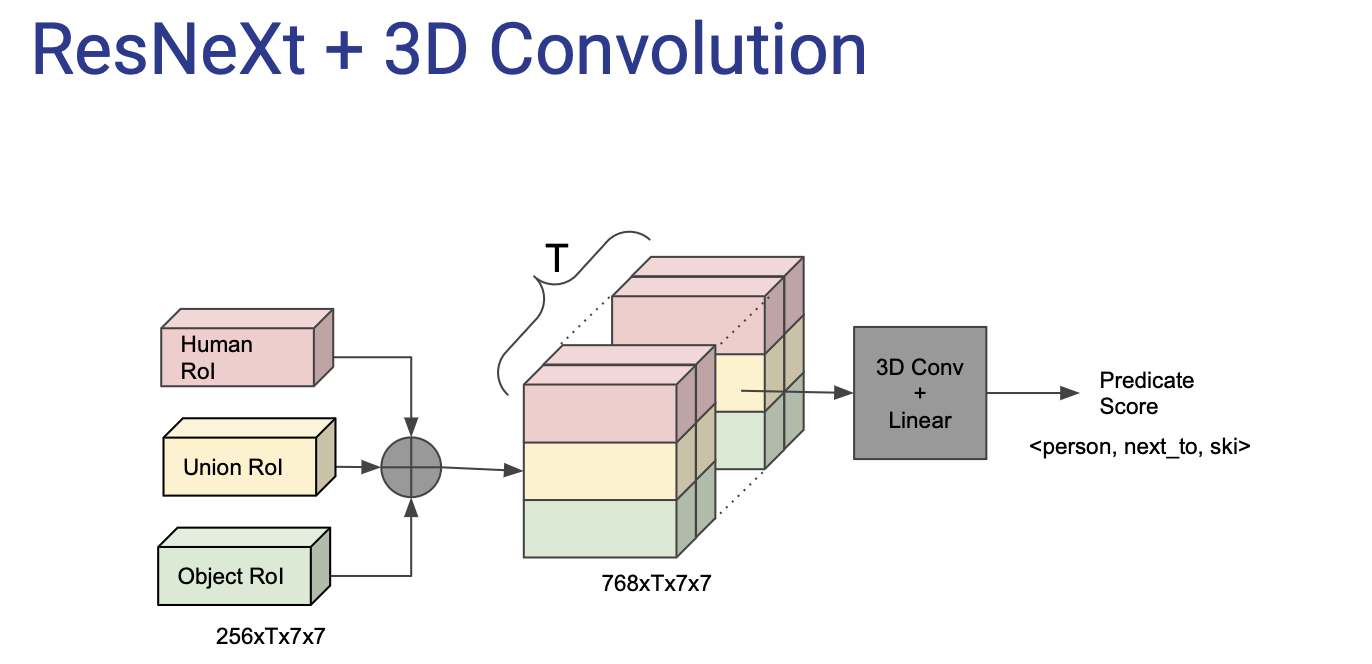
1) We propose an end-to-end
pipeline that infers multiple human-object interactions in
the video (c.f. Section 3.1). Our pipeline takes into account
human pose cues as well as factors in the positional priors.
We avoid over-committing to heavily occluded and truncated poses by
using a softer representation of heatmaps
2) We address nuances in the multi-label and
long-tailed nature of the dataset by formulating a class-weighted training objective
with propensity-weighted cross entropy loss/ focal loss for determining the weights. We also factor-in the muti-label nature of the problem using
a simple yet effective threshold tuning mechanism.
3) We identify and discuss issues
with the existing evaluation protocol and propose a solution
that is consistent with the existing evaluation setups.
Pipeline
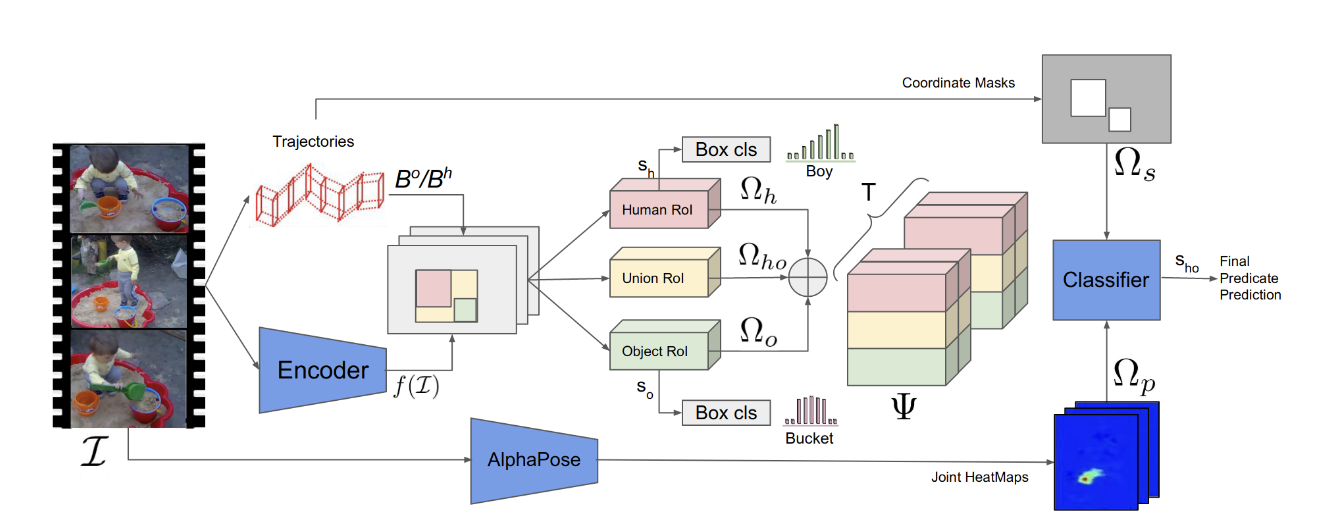
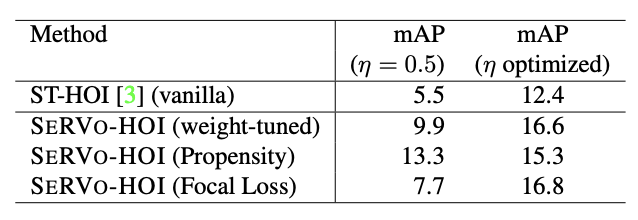
Ablation studies
We now analyse the design choices primarily through two lenses: loss methods and network designs.
1) Loss methods: All the variants improve performance on rare classes compared to the baseline models. Weight-tuned CE, while performing better, has been extensively tuned for multiple
values. Propensity weighing requires minimal tuning and is actually a more efficient choice in this regard. We also note that while ST-HOI and unweighted Cross-Entropy trained models lead to degenerated confusion across the two most abundant classes, using weight-tuned Cross-Entropy and Focal Loss noticeably disperses the confusion and produces stronger diagonals.
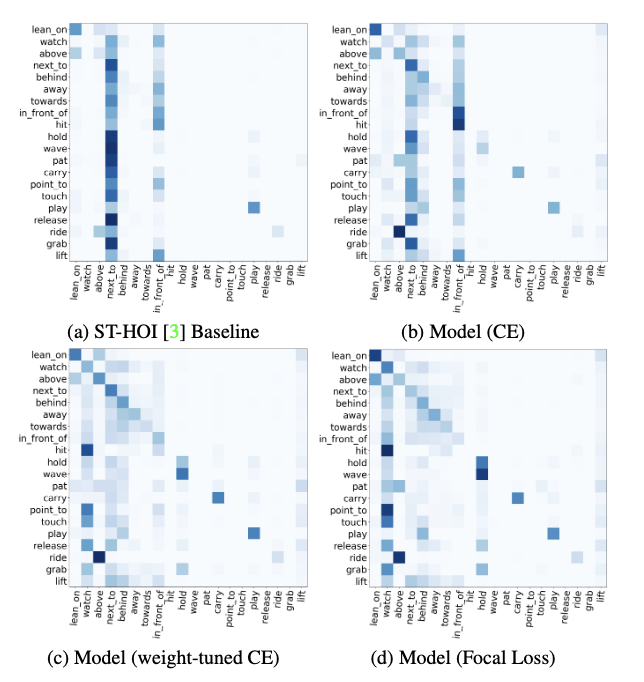
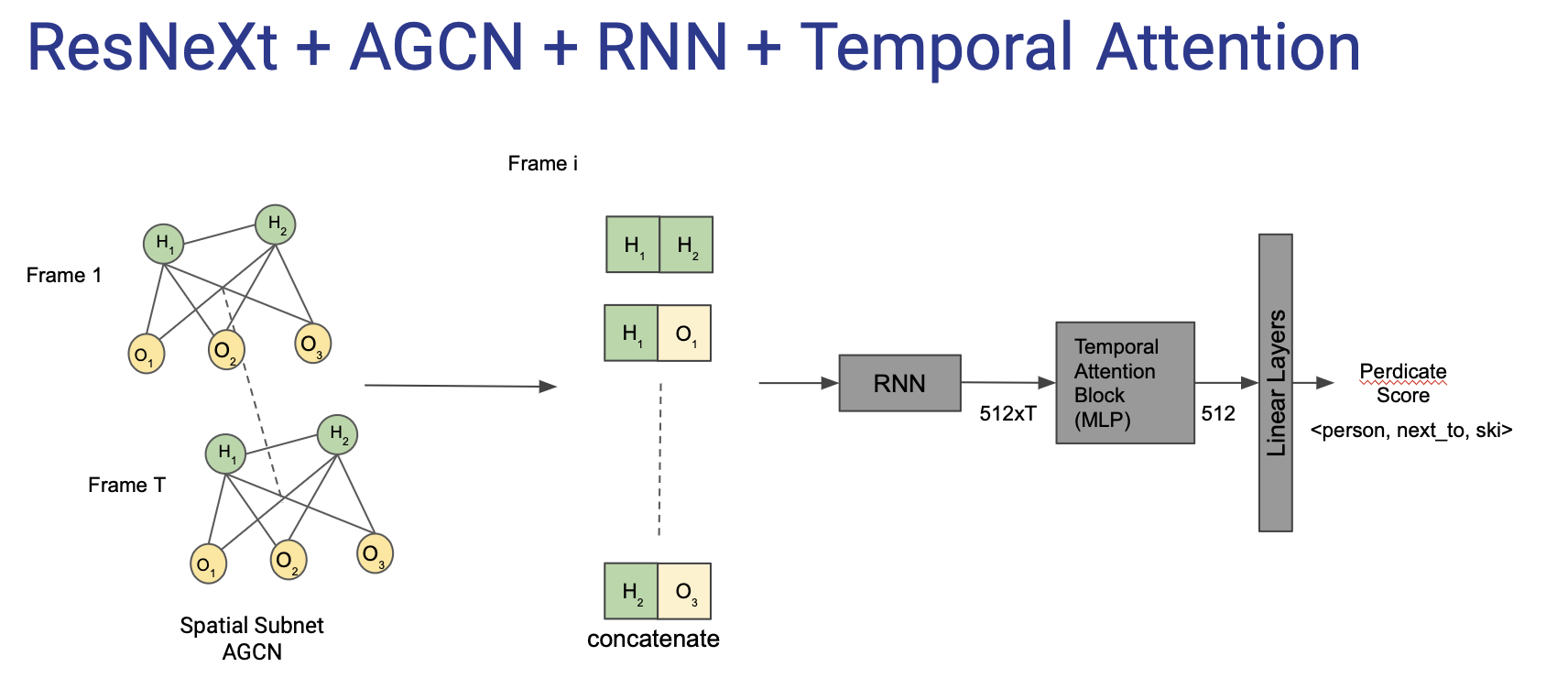
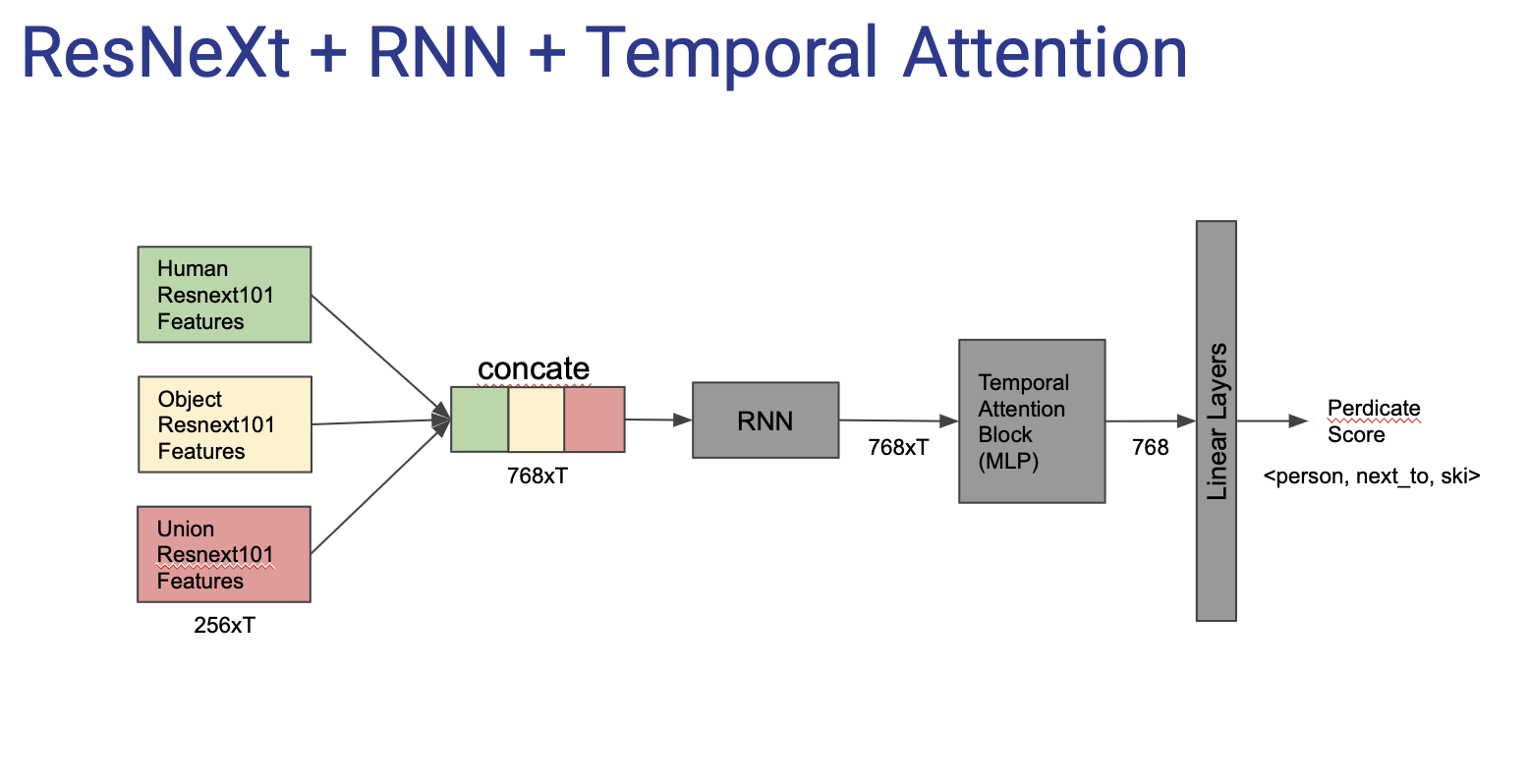
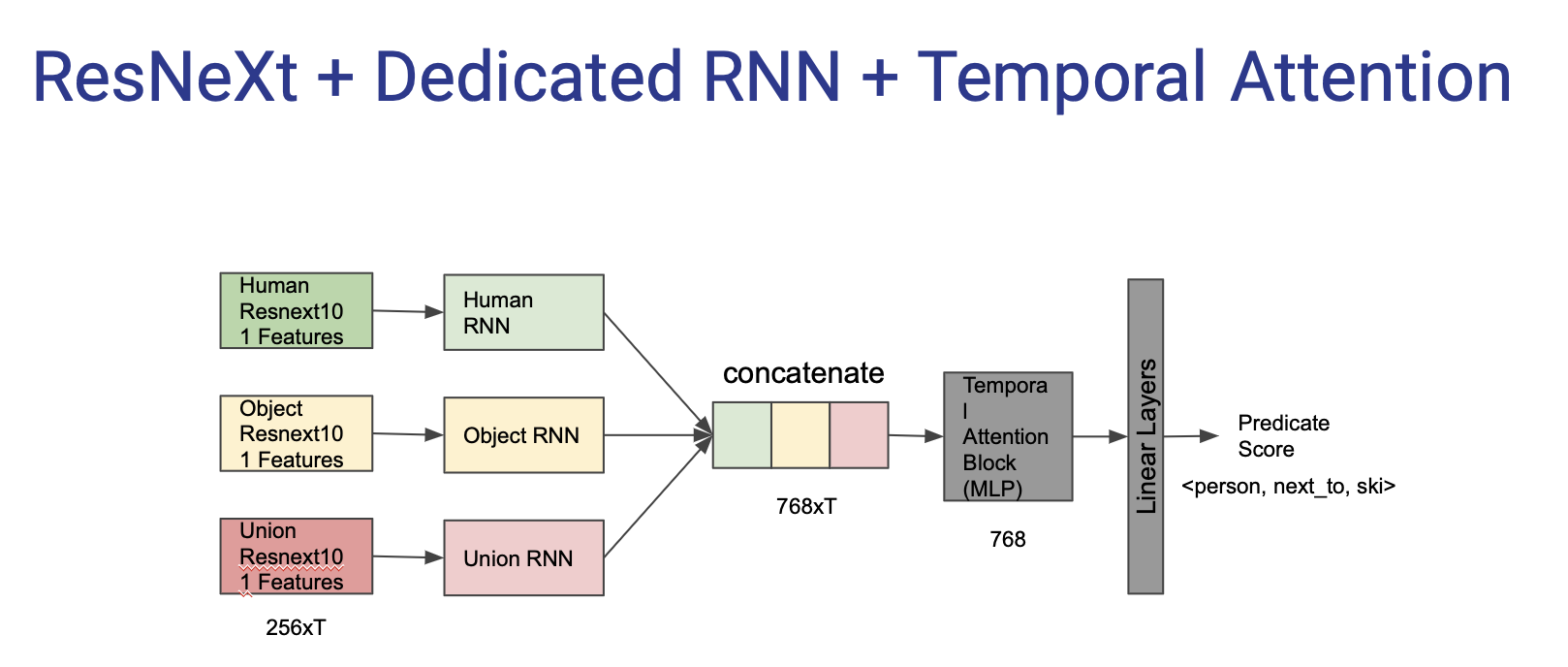
2) Network Design: We experiment with several architectural design choices. We attempted learning temporal relationships with an RNN-like sequence model as an alternative. We also experimented with graph convolutions to model the inter-object relationships in the spatial context. However, we found the SERVO-HOI to be the most optimal in terms of performance and simplicity. We confirm that adding union features help but also observe that addition of human pose features does not improve performance.

Conclusion and Future Work
We achieve state-of-the-art results by carefully crafting a network that accounts for the spatial and postural cues of the human body. Our pipeline improves the state-of-the-art by a significant margin on multiple protocols. We achieve a mean Average Precision (mAP) score of 21.2% compared to 17.6% on the challenging VidHOI dataset. Note, that this is a 20% improvement and a significant improvement on VidHOI tasks. On another evaluation mode (detection), we improved the mAP by 50%, achieving 4.8% compared to 3.2% of the best method.
In addition to this, we address the problem of dataset-skew and demonstrate improved performance on rare classes. Finally, we discuss issues with the existing evaluation protocols and propose solutions to avoid them. In future, we intend to fur- ther work on the long-tail label distribution problem in the context of HOI as also propose a pipeline for holistic HOI detection and recognition.