Our work aims to provide a a comprehensive summary of the different approaches taken towards Human Pose Estimation, along with recent developments using self-supervision. Human Pose estimation is a Computer Vision problem which estimates the pose of humans either from images or videos, in 2D or 3D. It presents the advantages of using such self-supervised networks as compared to CNN based approaches commonly used. We also look into some experiments using a combination of pre-training and fine tuning with BERT models for Future Pose Prediction, which paves the way for future works in this field.
Self-Supervised 3D Pose Estimation from Monocular Videos
Objective:
3D in-the-wild data is costly and challenging to obtain. Most works on 3D pose estimation use real world 2D data along with 3D data from datasets like Human 3.6M and MPI-INF. These datasets are shot in controlled environments, and hence are biased. We aim to only use monocular videos for learning the pose representation.
Prior Work:
There are 3 literatures that we find very useful.
1) Mitra et al. (CVPR, 2020) learns a multi-view consistent pose embedding. They perform hard negative mining, and use metric learning to ensure similar poses have similar embeddings 3D Pose is learnt as a complimentary task in this multi-task setting.
2) Honari et al. (arXiv, 2020) learns pose embedding from monocular video using self-supervision. In pre-training, the encoder learns to predict a time-variant embedding and another time-invariant embeddings per frame, which are then used to reconstruct image. Pairwise all the frames are compared, and a temporal distance based similarity loss is applied to get the embeddings.
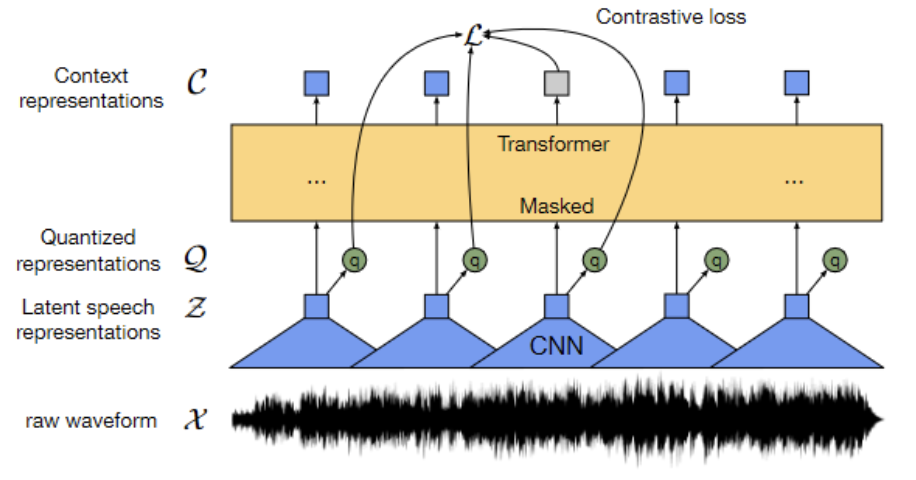
3) In the speech domain, wav2vec2 model (Baevski et al., arXiv 2020) learns contextualised speech representation in an unsupervised fashion. Raw audio is fed into CNN module to get a latent speech representation. While the quantizer learns a finite set of speech representations via product quantization, the TransformerEncoder model is used to learn contextualised representations.
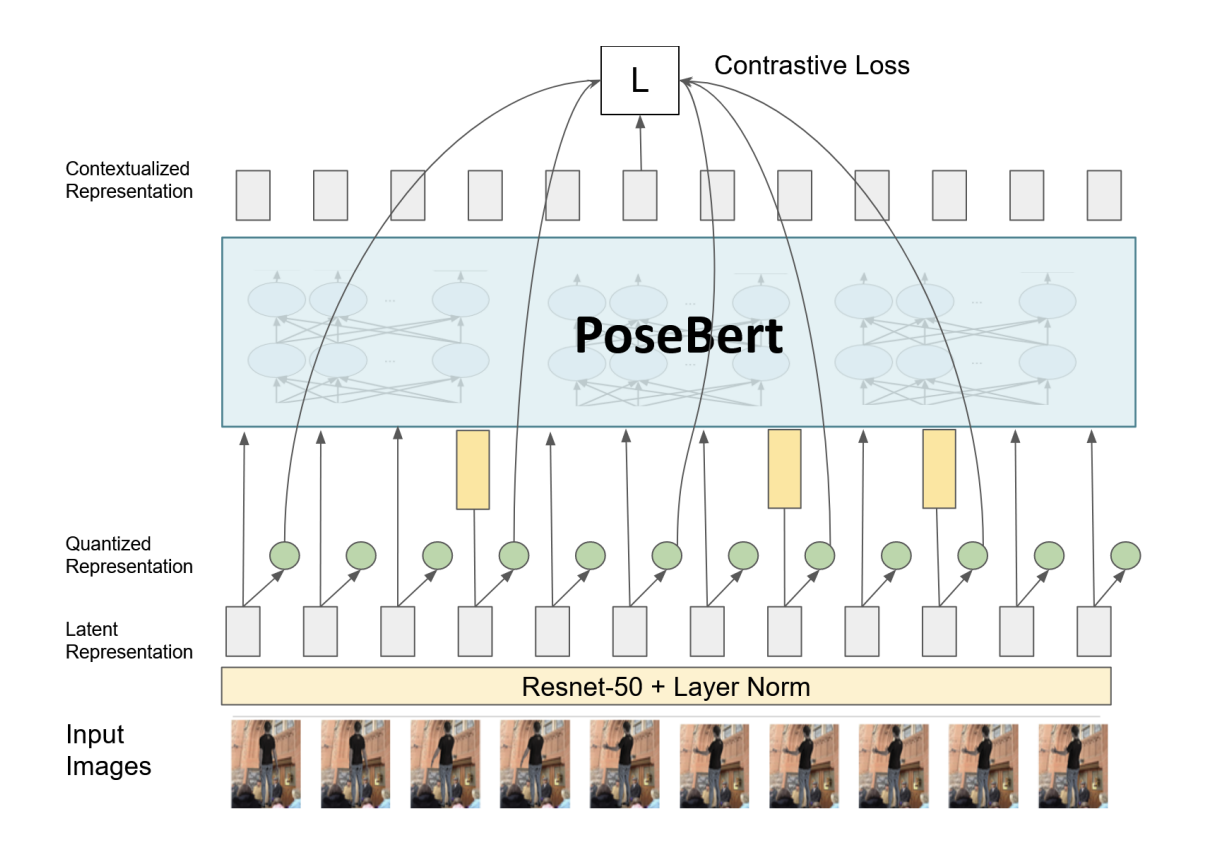
Pose-BERT Model:
Our model is inspired by the wav2vec2 model in speech domain. We feed input images a Resnet-50 network and instead of absolute encoding, relative positional embedding is added to this latent representation. Around 30% of frames are masked and passed through a BERT model. This model is trained via a contrastive task where the true latent is to be distinguished from distractors. Fine-tuning is done by performing pose-prediction with full supervision.
For evaluation, i.e to test the quality of embeddings after pre-training, we use the pose-retrieval metric. For each validation embedding, we retrieve the closest embedding in the train set and then compare the MPJPE(Mean Per Joint Position Error) score of the 2 corresponding poses.
Results:
We compare results for different sampling strategies over here in the presence/ absence of the background mask/ quantizer. In GT-Pose, pose is used for sampling negatives, while in Cosine-sim, the cosine-similarity between frames is used
1) Comparing the Top1 retieval MPJPE scores and the results for fine tuning for pose
estimation with and without the background mask:
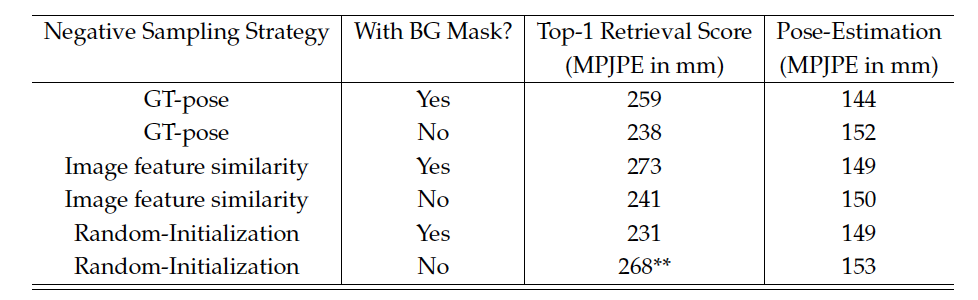
We see that with background mask, retrieval scores are much better for each sampling strategy. (**except for the random initialization). But for pose-estimation, we see that the our immediate pretraining (with contrastive loss) doesn’t seem to help much. We also see that that random initialization yields better results after pretraining with contrastive loss. This might be because either the contrastive loss is not a representative of the retrieval objective
2) In order to evaluate the contribution of the quantizer, we run experiments both with and without the it. Same frame from multiple views are considered positives while unrelated frames are negatives.
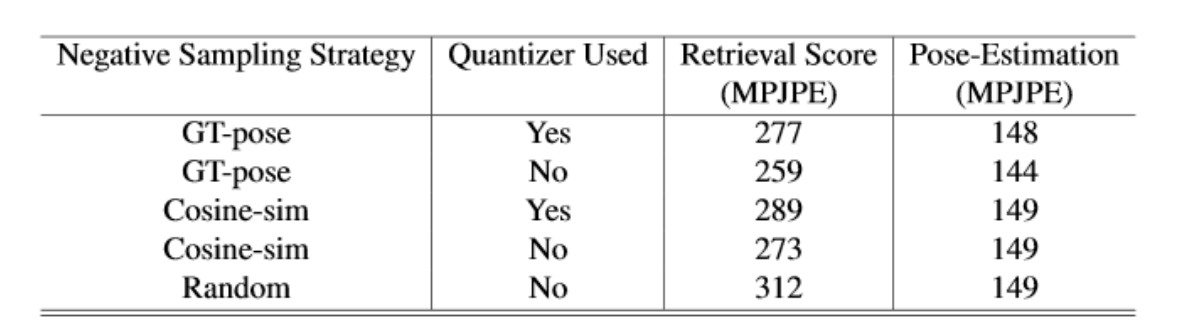
The retrieval scores for our models are observed to be quite high. Also, we notice that the experiments using quantizer tend to perform worse than their counterparts without it. More importantly, we observe that the choice of pre-training does not affect the final metric of the fine-tuning task. The pose estimation results are very close to each other, irrespective of the choice of negative sampling of the use of quantizer, which implies the sampling method has very little effect on the final pose estimation task.
Conclusion and Future Work:
Quantization as well as multi-tasking seems to be back firing, which needs to be looked into, in the future. Using retrieval metric on Contextualized representations also seems to be inappropriate on Human3.6 dataset. We conclude that our immediate pretraining doesn’t seem to help much in pose estimation, which again through modification in experiments needs to be taken care of. While neither of the evaluations have led to state-of-the-Art numbers, it is possible to take our model performing relatively well for a particular task, and add a few modifications to it to enhance its performance.
Future Pose Prediction
Objective:
Inspired by the recent success of transformer-based models in language generation tasks, we deployed the OpenAI-GPT2 architecture for predicting 3D human poses in an auto-regressive fashion. Given a sequence of poses, we intended to predict the future poses (upto 400ms for short term and upto 1 sec for long term predictions)
Pose-GPT Model:
We use a 2 layer OpenAI GPT2 model to model human motion. At training time, we schedule the rate at which the model sees its own output. At earlier epochs we feed more ground truth to the input, and we slowly increase the rate at which it sees its own prediction. Evaluation is then done in an auto-regressive fashion.
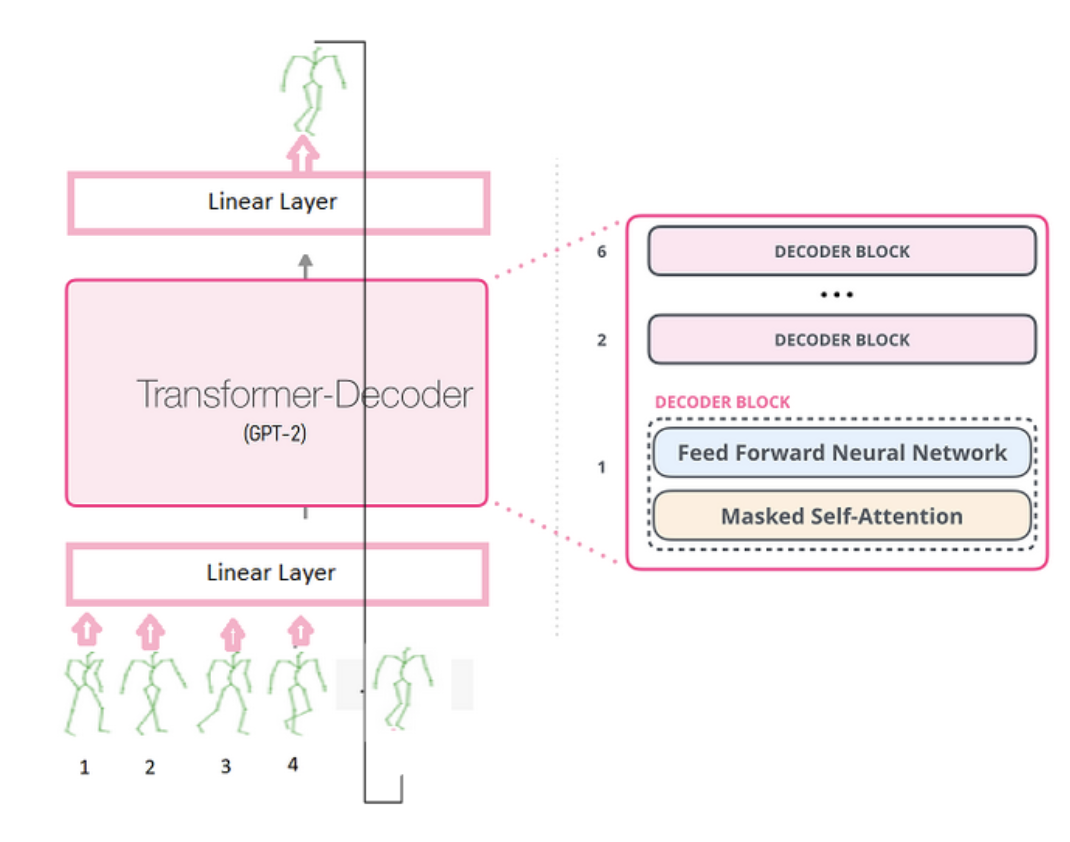
Comparison with Baselines:
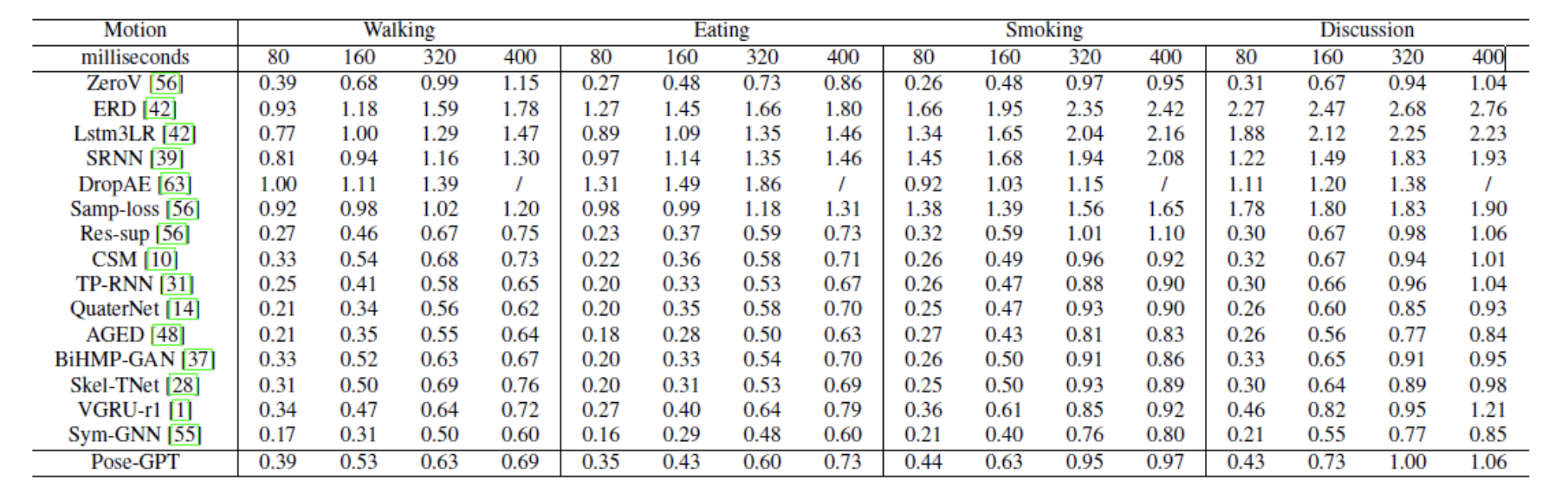
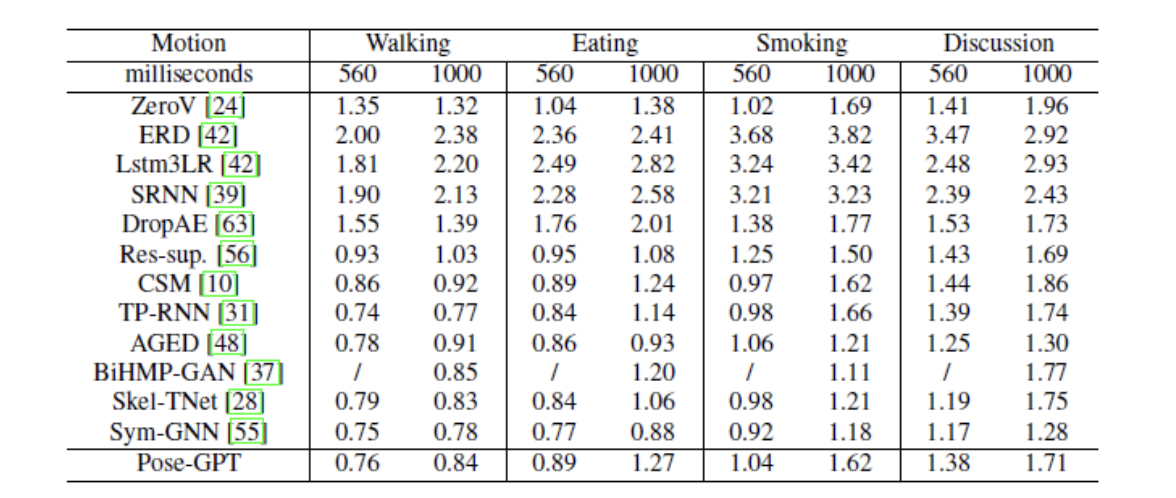
Conclusion and Future Work:
We achieved competitive pose errors with respect to state-of-the-art methods on
large-interval actions of the Human3.6M dataset but fell short on the smaller ones. The better numbers on longer intervals could be attributed to the self-attention feature of GPT model that
allows it to generate more plausible poses on the long run. Our hypothesis of masked self-attention aiding pose prediction was hence satisfactorily corroborated by the results on large interval actions. On the 4 representative actions of Human 3.6M, our results on Walking action is the closest to the
SOTA model on the longer time intervals (560ms and 1000ms).
The initial hypothesis of self attention to aid pose prediction over larger time intervals is mildly corroborated by the results, although further investigation into the attention weights will provide useful insight regarding the short time interval results. We leave further experiment and ablation
studies to future works.