Any behaviour that is considered abnormal or doesn’t fit in can be considered an anomaly. Anomalies in Proctored Videos are detected in case a student’s behaviour is suspicious which could imply a high chance of cheating in the examinations. In an attempt to detect anomalous behaviours in online exams and implement a way of Automated Proctoring, we hereby try to design an auto-encoder model based on human pose features which would give an idea how anomalous the video clip is. Possible actions of students giving exams can be classified as anomalous and non-anomalous.
Some examples of anomalous actions can be using
a phone, standing up and walking away from the laptop screen, or another person
entering the camera’s view etc as shown:

Non-anomalous or normal behaviour expected from the students giving exams
would be a few hand or neck movements, drinking water, reading or writing, checking
their watch for time etc as shown:

Proposed Pipeline
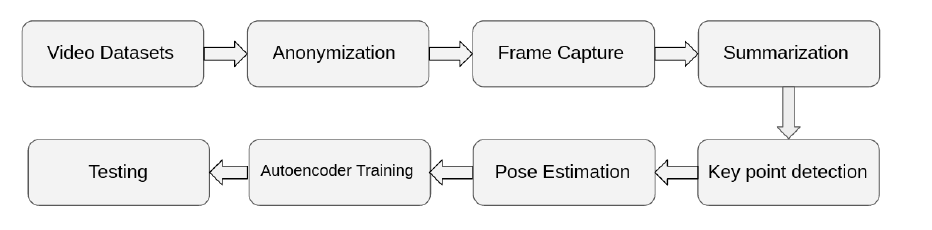
|
Results:
We obtained the best results after using the shown autoencoder, training on the multiple video datasets with ReLU activation function. After normalization, final loss during training is of the order of 10ˆ-6.
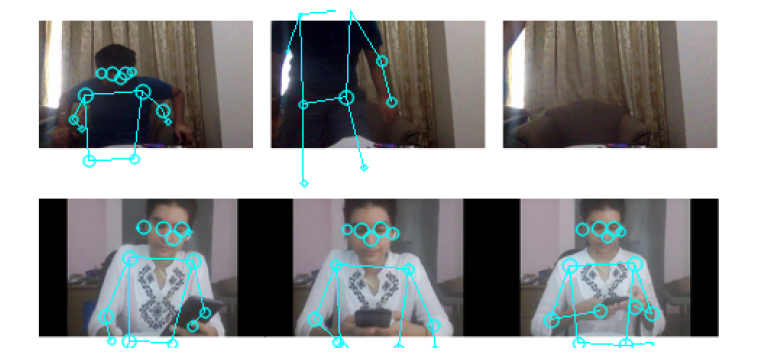
Frames with minimum reconstruction loss (in the order 10-3 to 10-2) were obtained
from the non-anomalous videos while the ones with high reconstruction loss were
from anomalous ones(1-100). The posenet and the test results for the example images shown above are:

Conclusion and Future Work:
Autoencoder training and testing for NTU-RGB Dataset with n degrees of anomalies in actions needs to optimized and testing should be made into a n-class classification problem. The other way to work on this would be to rank the frames in descending order of reconstruction error (Rank 1 is most difficult to reconstruct and that frame is the most anomalous. We also need to consider the optical flow between frames so as to comment on video segments instead of just infering from the frames.
Efficient Anomaly detection and Automated Proctoring using posenet features for different modes of exams needs to be implemented. Synchronous setting needs to be explored further into, video-MMR could be a good start for this.